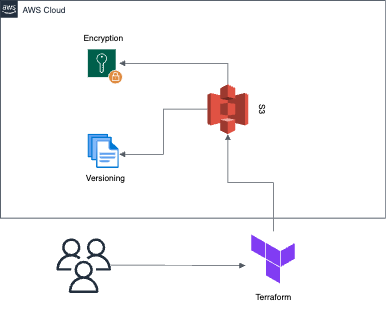
It’s considered a best practice to store a Terraform state file in a remote backend for better accessibility, management, and security of course. Terraform State files contain the mapping of Terraform configurations against real-world deployments and are created at the very beginning of the execution of these configurations. All the changes after the first execution will always be validated by the same state files to make sure the intended changes are applied.
In this blog post, we will configure an AWS S3 bucket as a remote backend for our Terraform configuration.
Why do we use a remote backend?
By default, Terraform stores the state file in the root of our project (local backend) along with the Terraform config files. There are two main reasons why it’s recommended to store the state file in a remote backend.
- The state file as mentioned above stores the mapping of Terraform configurations against the real-world deployment, hence, it contains important information that should not be made public. For instance, your Terraform configuration might provision an RDS instance on AWS. The login information for that instance will be stored in the state file in human-readable form. That is why, it’s important to store the state file in a remote setting where it’s secure and can be accessed securely.
- Second, if multiple developers are working on the same configuration files and each has their own version of the state file, it can eventually bring about inconsistency in the deployments and can cause high infrastructure cost implications. Having a remote backend can solve this issue. In this case, we also need to implement a locking mechanism for state files. For instance, a Terraform operation is performed (plan, apply, destroy) that will modify the state file, while the operation is being performed by Terraform, if another operation is executed it will bring about a race condition. To avoid this, state files need to be locked for the duration of an operation and if in the meantime another operation is executed, it will be queued. Dynamo DB is used for this purpose but that’s a topic for another time. If you want to know more about it you can visit the official docs.
Implementation of S3 Backend
Setting up an S3 backend for any Terraform project is quite straightforward. Before you start make sure you have Terraform installed and have AWS CLI configured.
-
First, we will create an S3 bucket.
-
Give your bucket a name. S3 bucket names are unique globally so you might have to try different names.
-
Make sure all public access is blocked.

-
Enable bucket versioning.
-
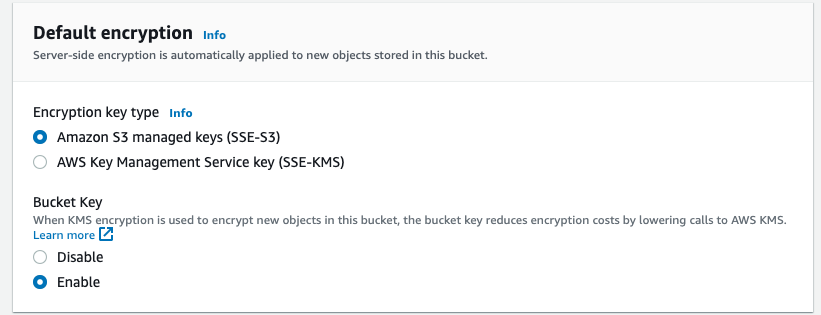
Enable Encryption. You can also use KMS encryption for better security but for that you will have to specify the KMS key in the backend configuration block.
-
-
Once the bucket has been created, create a
main.tffile in a directory of your choice and add the following terraform configuration in the file.terraform { required_providers { aws = { source = "hashicorp/aws" version = "~> 4.16" } } backend "s3" { bucket = "mybucket" key = "path/to/my/key" region = "mybucket-region" encrypt = true profile = "myprofile" } required_version = ">= 1.2.0" }Add the relevant information of your bucket in the backend configuration block. The
bucketis your bucket name. The
keyis the path to the state file inside the bucket, you can set it asstate/terraform.tfstate. Theregionis your bucket region. You don’t needprofileif you are using your default AWS CLI profile. If you are not change it to the name of the profile you want to use. You can get a list of all configured AWS CLI profiles using the command
aws configure list-profiles -
Use the
terraform initcommand to initialize your configuration and to see if you are able to access your S3 bucket. If everything goes right, you will see the following output.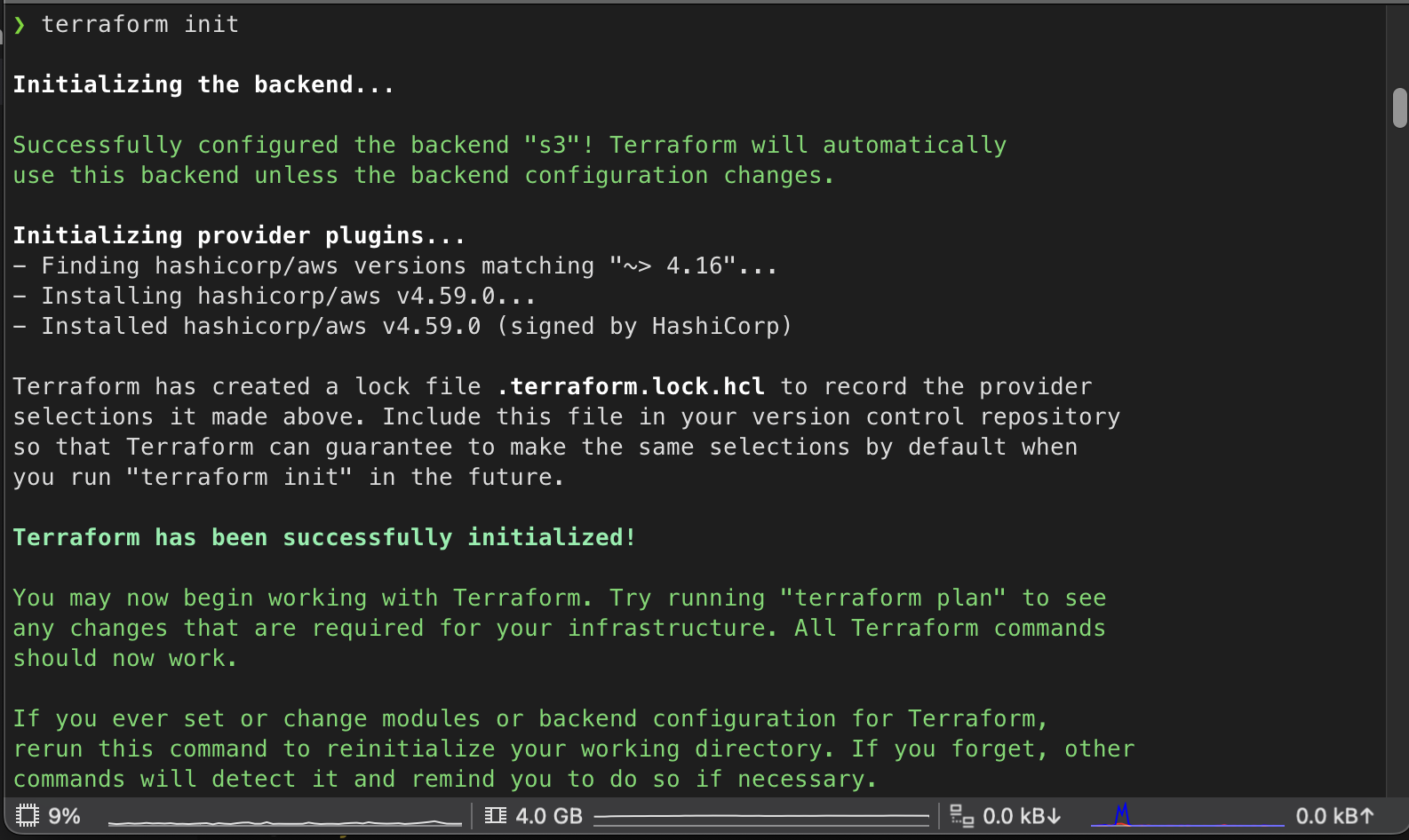
For now, there is nothing in the S3 bucket because we haven’t executed any operations yet. Let’s do that!
-
Let’s configure the terraform
main.tfto deploy a simple EC2 instance. Add the following configuration in the terraform file to deploy an EC2 instance.provider "aws" { region = "us-east-1" profile = "myprofile" } resource "aws_instance" "app_server" { ami = "ami-0557a15b87f6559cf" instance_type = "t2.micro" tags = { Name = "My Example VM" } }The above configuration will deploy an EC2 instance in the us-east-1 region with the defined configuration in the resource block.
-
Initialize the terraform configuration again and then use
terraform applycommand to apply the changes. The apply command will provision the EC2 instance in the AWS account.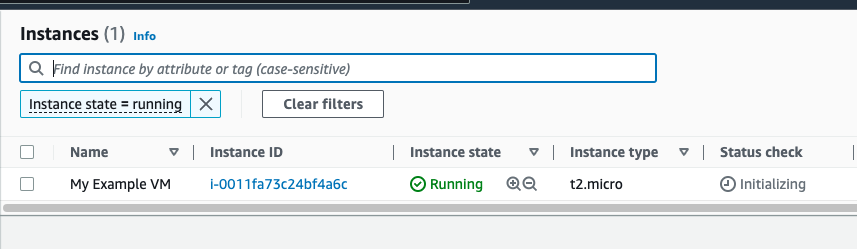
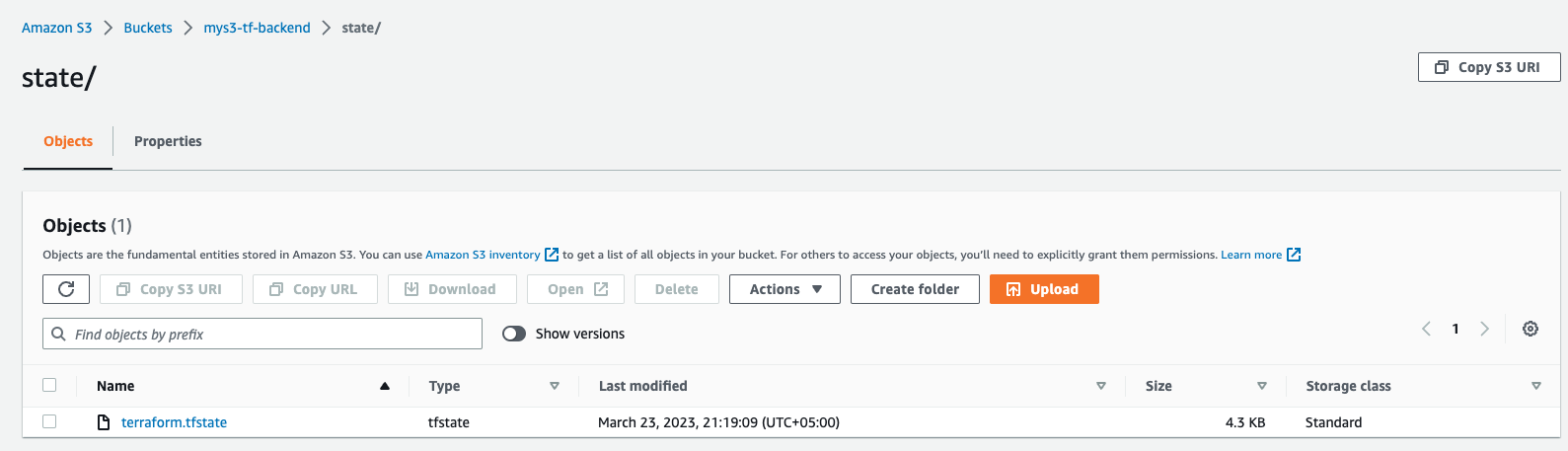
This operation will also generate a state file that will hold all the information regarding this deployment and will store that state file in the configured S3 backend. So, if you go and check your S3 bucket, there will be a state file in the state folder.
-
Make sure to destroy the Terraform deployment using the
terraform destroy.
That’s it. You have configured an S3 backend for your project. There were a lot of manual steps in using the AWS console to set up the backend but you can also set it up using Terraform configuration itself. Just make sure that these configurations are not part of the project’s Terraform configs.